
Cut Your AI API Costs by 40–75%
A smart proxy that sits between your app and your AI provider. It routes requests to free/paid models, caches identical calls, and tracks savings – no code changes required.
The problem
Every AI API call costs money – even when users ask the exact same question twice. Duplicate requests, simple prompts, and inefficient routing waste your budget.
Cache44 solution
Intercepts each request. Simple prompts go to free models (Groq, Gemini, Qwen). Duplicate calls come from cache. Complex tasks use paid models. You pay less, automatically.
How it works
Three simple steps to lower your AI bill
Add your API keys
Bring your own keys – free models (Groq, Gemini, Qwen-Turbo) or paid (OpenAI, Anthropic, DeepSeek). We never store them permanently.
Point your app
Change one line of code to use our proxy URL: https://cache44.fly.dev/v1. Keep your existing OpenAI‑compatible client.
Start saving
Your dashboard shows every cache hit, dollars saved, and which provider handled each request. No surprises – just lower bills.
Smart features, real savings
Everything you need to cut AI costs without changing your workflow
Smart Routing
Short prompts → free models (Groq, Gemini, Qwen). Long/complex → your paid provider.
Exact Cache
Identical requests served from cache – second user pays $0. No duplicate charges.
BYOK
Your keys, your control. Encrypted, never logged. Bring your own OpenAI/Groq/Anthropic keys.
Live Dashboard
See total saved, cache hit rate, and per‑request cost breakdown in real time.
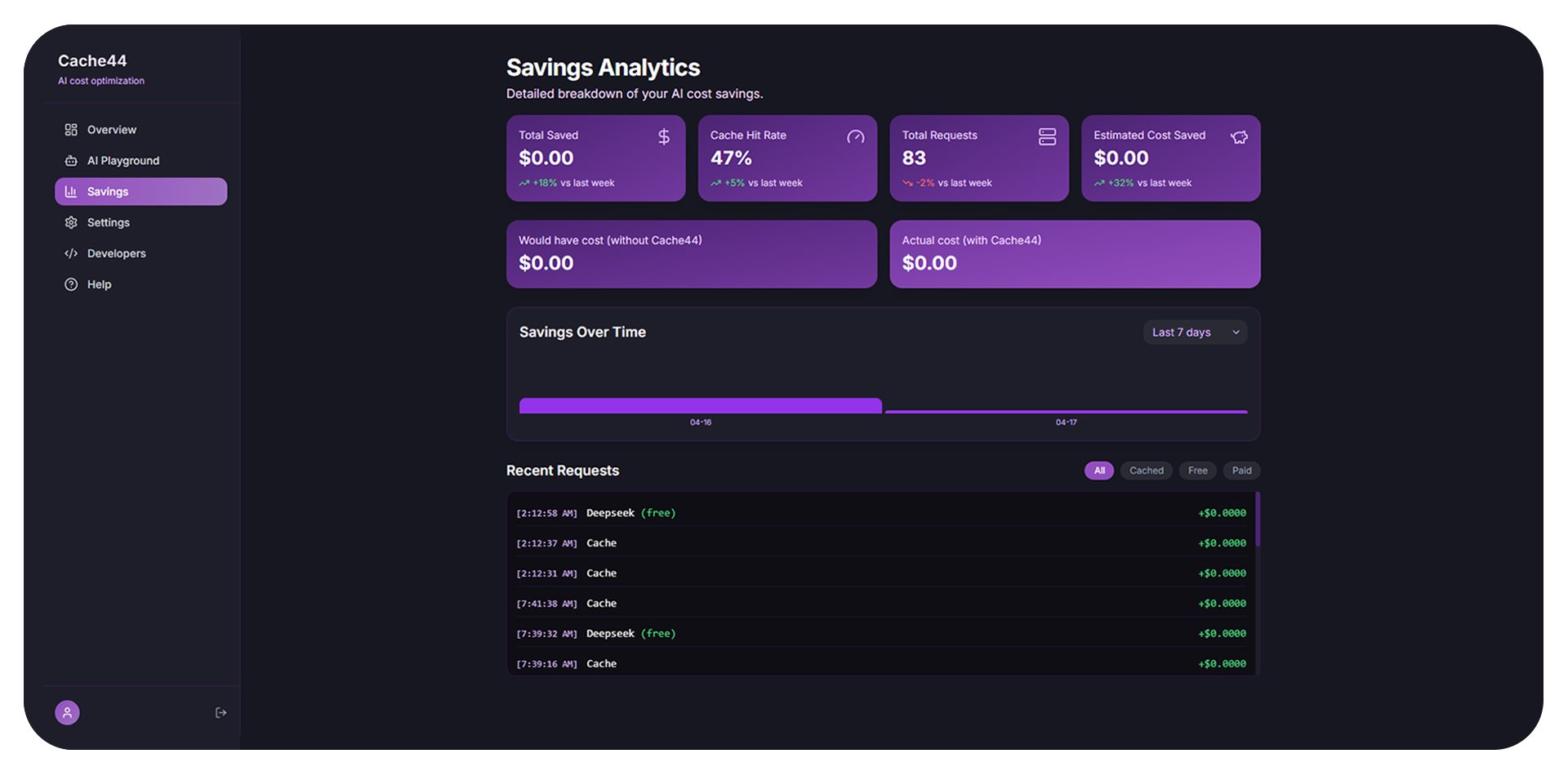
See your savings in real time
Every cache hit, every dollar saved – right in your dashboard.
Supported providers – bring your own key
+ more coming soon
Ready to cut your AI bill by 40–75%?
Join beta users already saving thousands on API calls.